Как смикшировать озвучку с максимальным качеством
Создателям пиратских DVD посвящается
Содержание :
Сначала хочу уточнить, что я понимаю под качественно наложенным переводом.
Это:
1) Когда в конечном результате как можно лучше слышна оригинальная
игра актеров, и при этом четко слышен голос переводчика. В конце концов не
зря же им (актерам) платят бешеные деньги. При уничтожении оригинального звука
уничтожается половина фильма (и часто –лучшая).
2) Когда полностью сохраняется оригинальная объемная картина звука (т.е. звучание
должно быть максимально приближено к оригиналу).
Если вы стремитесь к тем же идеалам, то описанный ниже набор технических приемов поможет вам получить максимально качественный результат. В противном случае эта статья для вас бесполезна.
Этот материал рассчитан на людей, уже знакомых с основами работы с видео и звуком. Поэтому некоторые общеизвестные вещи не будут здесь подробно рассматриваться. Советую предварительно почитать статьи с http://divxhome.bmtelecom.ru/
Итак, список необходимых для работы инструментов:
|
Как называется. |
Где можно найти. |
|
Sonic Foundry Soft Encode |
http://websound.ru/ |
|
Cool Edit Pro 2.0 или 1.2 |
http://websound.ru/ |
|
Прямые руки. |
Попробуйте поискать рядом с собой. :-)
|
|
Уши, растущие на голове, а не на другом месте. :-)
|
Это либо есть, либо нет. Хотя после упорных тренировок они обычно смещаются в правильном направлении. :-)
|
Работать будем с исходной 5.1 канальной AC3 дорожкой. На выходе
тоже будем иметь AC3 дорожку с наложенным переводом. С полученной таким образом
дорожкой можно делать разные вещи - в частности, преобразовать в 3D стерео с
помощью Advanced Encode Decode Tools.
Но это тема для отдельного разговора.
С помощью Sonic Foundry Soft Encode открываем исходный файл.
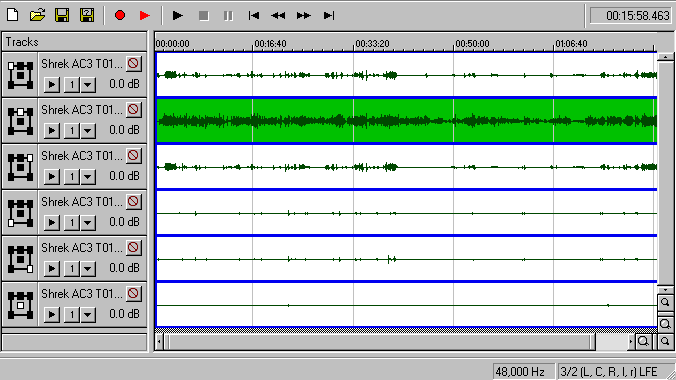
Отсюда нам нужно выдрать центральную дорожку (выделена зеленым).
Самый простой способ – закрыть все остальные каналы и сохранить результат в виде wav-а.

Преимущество этого способа – экономия места на винче.
Недостатки – лишние 10 минут на повторное открытие AC3-шной дорожки.
Существует три “священных” правила работы с многоканальным
звуком, при соблюдении которых получается дорожка, практически идентичная исходнику.
- Правило 1. Уровень звука в заново смикшированном центральном канале должен быть как можно ближе к оригиналу. Обычно при микшировании озвучки уровень центрального канала повышается, что приводит к завалу стерео картины. Слушать такую дорожку на пятиканальной аппаратуре еще вполне возможно, но при преобразовании в стерео центральный канал будет забивать остальные. Если же при микшировании понизить уровень оригинального звука в центральном канале, то это приведет к провалу и искажению в центре стерео картины.
По моему опыту в 99% случаев правило 1 не соблюдается. В результате на большинстве DVD либо “убито” стерео, либо “завален” центр, либо и то и другое вместе. Подобный испорченный звук благополучно перекочевывает на DivX рипы и необратимо портит впечатление от фильма.
Из описанного видно, что правило 1 устанавливает очень жесткие ограничения на уровень микширования перевода. И для того, чтобы добиться хорошей слышимости перевода, приходится идти на всяческие ухищрения. Гораздо проще преобразовать дорожку в стерео и только потом накладывать перевод. При этом при не очень качественном микшировании звук портится в меньшей степени. Поэтому если вы не вполне уверены в своих силах - не пытайтесь работать с многоканальным звуком.
- Правило 2. Центральный канал должен быть идеально синхронизирован с другими каналами. Сдвиг даже на несколько миллисекунд недопустим. Представим, что по действию фильма происходит взрыв или выстрел. Если во всех каналах он произойдет в один момент, а в центральном со сдвигом, печальные последствия для стерео картины, я думаю, очевидны.
Это правило обычно соблюдается само собой, но бывают печальные исключения. Ребята из Мосфильма, делающие “Полные дубляжи”, ухитряются создавать местами сдвиги в 100- 200 миллисекунд. Подобный звук я называю “глухой озвучкой” т.к. оригинальный трек там полностью изничтожен. Нет более полного и всеобъемлющего способа испортить звук, чем тот, которым пользуются эти товарищи.
-
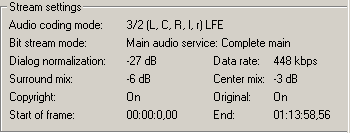
Правило 3. Звуковая дорожка должна быть закодирована с теми же параметрами микширования, как и исходная дорожка. Эти параметры выводит Soft Encode при открытии дорожки.
Обычно это правило тоже соблюдается, т.к. большинство файлов кодируется со стандартными установками. Но бывают исключения. Например, в этом саундтреке уровень Surround mix установлен в –6 децибел в место обычных –3 децибела.
После сохранения центрального канала запускаем Cool Edit Pro.
Первым делом надо синхронизовать имеющийся файл(или файлы) озвучки с оригиналом.
Переходим в мультидорожечный режим. На одну дорожку выкладывается оригинальный
центр, а на другую файл(или файлы) озвучки. В процессе синхронизации я обычно
режу озвучку по паузам между фразами, сдвигая куски так ,чтобы голос переводчика
начинался через 100 – 300 миллисекунд после начала оригинальной фразы.
В процессе синхронизации надо постоянно контролировать получающийся звук, периодически прослушивая участки дорожки.
Конечный результат выглядит примерно так:
После синхронизации нужно аккуратно выделить только нарезанную озвучку. При этом зона выделения должна начинаться с нулевой отметки.
Выбираем: Edit->Mix Down to File -> Selected Waves (Mono). В результате получается синхронизированный трек с голосом переводчика.
После этого настало время непосредственно приступить к обработке
и микшированию звука.
Но сначала небольшое отступление. В дальнейшем в тексте будут часто упоминаться децибелы. Поэтому, для тех, кто не очень понимает, что это такое, небольшая техническая справка.
Децибелы - это логарифмическая мера отношения одной величины к другой.
Вычисляются они по формуле 20log10(измеряемая величина/опорная величина).
То есть децибелы бывают только относительно чего-то, и, говоря об уровне в децибелах, нужно всегда объяснять, относительно чего он измерен.
Измерение в децибелах очень удобно при работе со звуком, т.к. человек воспринимает уровни звука тоже по логарифмической шкале. Следовательно, соотношение уровней, выраженное в децибелах, с точки зрения человеческого уха линейно. Для примера +3 децибела кажутся в два раза меньшим увеличением уровня сигнала, чем +6 децибел, а +20 в два раза большим, чем +10.
Для быстрого перевода децибелов в “разы” достаточно запомнить несколько простых соотношений.
|
Децибелы |
Разы |
|
3 децибела |
1,5 раза (примерно) |
|
6 децибел |
2 раза (почти точно) |
|
10 децибел |
3 раза (примерно) |
|
20 децибел |
10 раз (точно) |
При сложении децибел “разы” перемножаются. Например, 16 децибел - это приблизительно 3*2=6 раз. Этих соотношений вполне хватает для повседневной работы.
В опциях Cool Edit-а можно включить отображение уровней звука в децибелах, что я настоятельно и рекомендую сделать.
|
Для того, чтобы повысить разборчивость озвучки и при этом не испортить оригинальный звук, нужно осуществить два мероприятия.
1). Компрессировать исходный голос переводчика. При компрессии
звука существенно уменьшаются колебания уровня громкости исходника, а энергия
голоса упаковывается более компактно, что существенно повышает разборчивость
речи при низких уровнях микширования.
2). Создать механизм поддержания оптимальной разницы уровней
звука между переводом и оригиналом. Т.е. желательно, чтобы вне зависимости
от уровня оригинала разница между ним и переводом составляла некую оптимальную
и фиксированную величину.
По моему опыту, оптимальное соотношение между компрессированной озвучкой и исходником находится в пределе от +4 до +7 децибел. При таких уровнях микширования озвучка звучит еще четко, а оригинальный звук вполне разборчиво и детально слышен на заднем плане.
Преходим в режим редактирования отдельных треков Cool Edit-а и выбираем полученный нами ранее трек с синхронизированной озвучкой.
Выглядит он пока не очень хорошо.
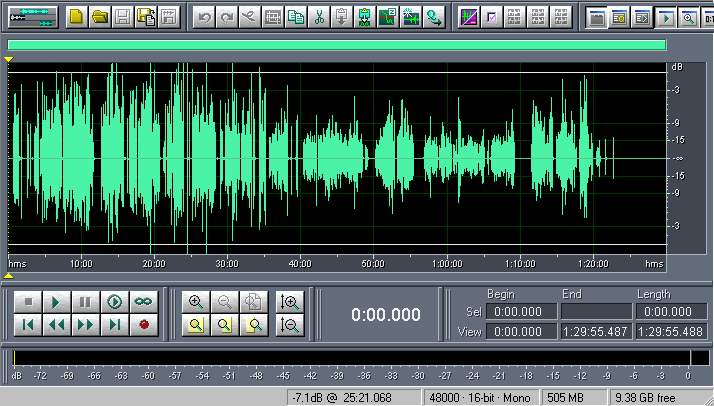
Видно, что уровень сигнала меняется в диапазоне, превышающем 15 децибел.
Для наших целей это совсем не годится.
Поэтому выбираем Effects -> Amplitude -> Dynamic Processing … , и сооружаем такую вот хитрую конструкцию.
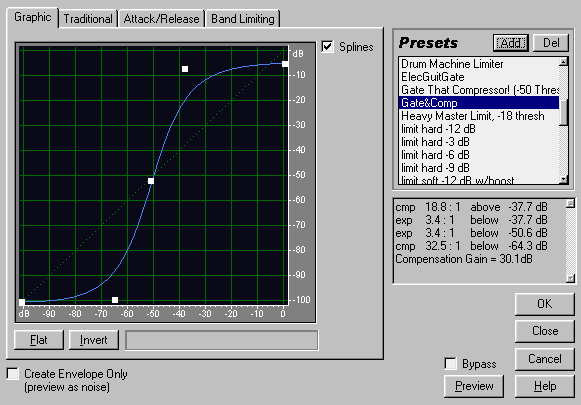
Нижняя часть этой кривой работает как Gate, отсекая неизбежные при записи звука шумы и призвуки. Верхняя часть - как компрессор, рассчитанный на диапазон изменения уровня озвучки в пределах от 0 до –25 децибел относительно максимального уровня сигнала.
Качество полученного подобным образом звука сильно зависит от настроек компрессора.

Хочу обратить особое внимание на нулевое время срабатывания Level Detector-а. Если этого не сделать, в конечном файле могут появляться очень неприятные выбросы.
В результате получаем совсем другую картину .
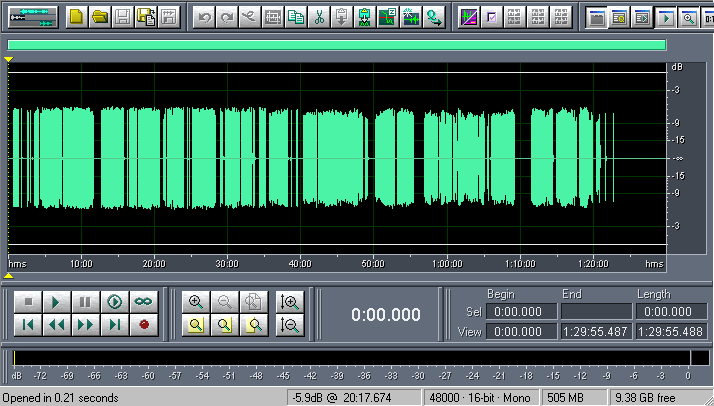
Небольшие колебания уровня сигнала еще остались, но более сильную компрессию делать не стоит, т.к. можно испортить качество звука.
Переходим снова в режим мультидорожечного редактора.
Для того, чтобы выдерживать нужную разницу между оригиналом и озвучкой, воспользуемся следующим техническим приемом. В момент звучания голоса переводчика будем динамически понижать уровень центрального канала, а во время пауз восстанавливать. Как это делать - зависит от личных пристрастий. Мне, например, нравится устанавливать уровень модуляции в -6 децибел и микшировать перевод с уровнем 0 децибел. При этом голос переводчика звучит с тем же уровнем, что и оригинальный голос, но тот как бы уходит на второй план во время звучания перевода и восстанавливается обратно в паузах.
Однако массовый слушатель обычно хочет, чтобы перевод звучал несколько громче, поэтому здесь будет рассматриваться схема: -3 децибела модуляция и +3 децибела уровень микширования.
Выкладываем рядышком компрессированную озвучку и центральный канал. Выделяем
обе дорожки по всей длине и выбираем Effects -> Envelope
Follower...
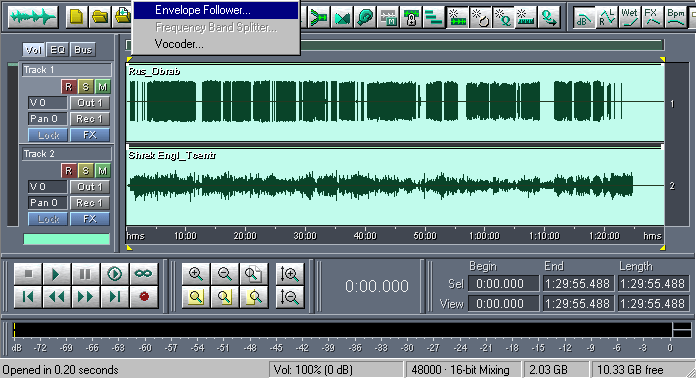
Это очень мощная примочка, про которую мало кто знает, и еще меньше людей умеют ей правильно пользоваться. Физически она представляет из себя компрессор, который управляется не уровнем сигнала в обрабатываемом канале, а уровнем сигнала другой дорожки .
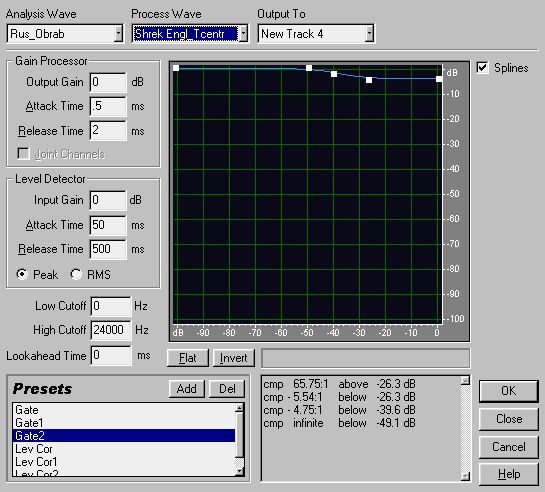
Из настроек видно, что когда уровень сигнала в канале озвучки становится больше –30 децибел, уровень оригинальной дорожки уменьшается на 3 децибела. В настройках советую обратить внимание на то, что время срабатывания Gain Processor-а много меньше времени срабатывания Level Detector-а. Если это условие не соблюдается, в конечном файле будут иметь место очень неприятные выбросы перерегулировки, причем как положительные, так и отрицательные.
Итак, одну проблему мы решили, но осталось еще одна. Уровень перевода у нас практически не меняется, а уровень оригинального звука изменяется в широких пределах. В результате в тихих местах оригинальный звук будет полностью забиваться переводом.
Чтобы этого избежать, снова запускаем Envelope Follower, но теперь будем обрабатывать уже файл озвучки.
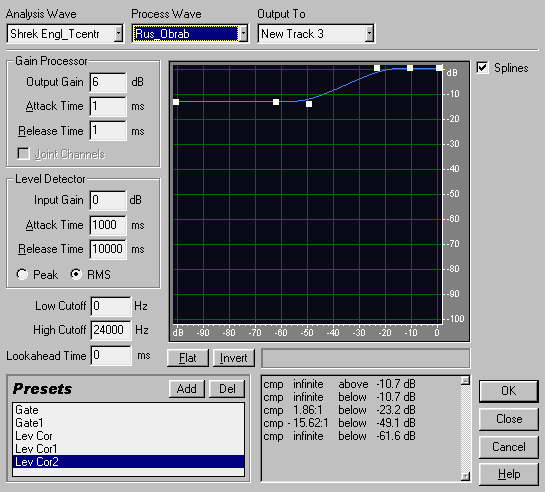
Хочу отметить, что, во-первых, степень уменьшения сигнала озвучки сильно ограничена, чтобы не допускать больших провалов в паузах оригинального трека, а во-вторых, времена срабатывания Level Detector-а выбраны такими, т.к. нам надо отслеживать только медленные, плавные изменения уровня центрального канала. Время срабатывания Gain Processor-а по прежнему должно быть много меньше, чем у Level Detector-а.
В конечном результате получается следующая картина.
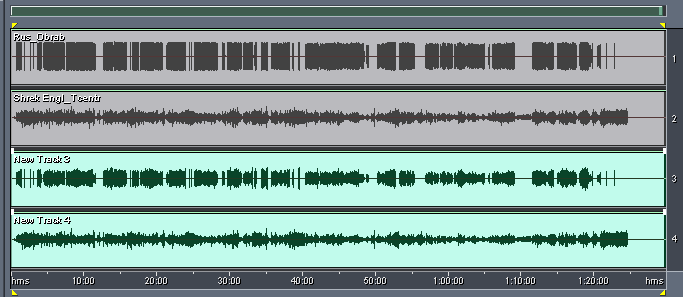
New Track 3 - это обработанный трек озвучки. Видно, что уровень сигнала в нем меняется теперь в широких пределах.
New Track 4 - это обработанный центральный канал.
Теперь отключаем звук в исходных дорожках и регулируем уровень микширования озвучки до достижения наиболее комфортного звука. Желательно проверить качество звучания в местах с различным уровнем громкости в оригинальной дорожке.
При этом уровень микширования обработанного исходника регулировать нельзя !
Добившись нужного звучания, выделяем две новые дорожки и выбираем:
Edit->Mix Down to File -> Selected Waves (Mono).
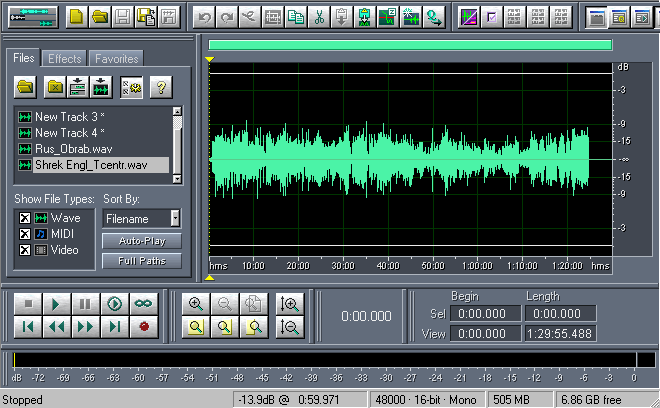
Проверить качество полученного результата можно, сравнив оригинальную дорожку с вновь созданной. Они должны быть максимально похожи по амплитуде.
Оригинальная дорожка:
Вновь созданная:
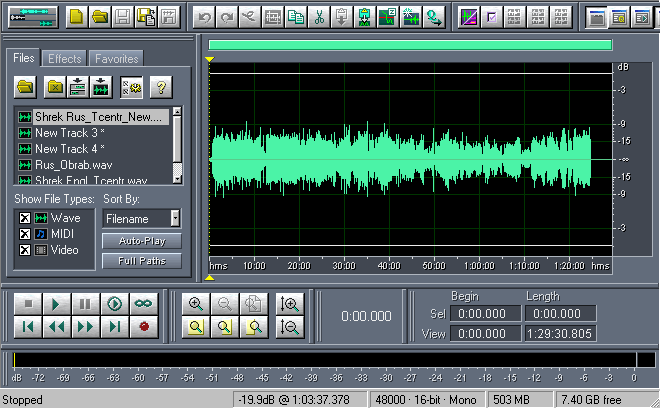
Если это не так, нужно поменять уровень микширования обработанного перевода.
Когда будет все в порядке, сохраняем полученную дорожку и заново запускаем Soft Encode.
Открываем исходную дорожку и удаляем центральный канал из проекта. После этого открываем вновь созданный трек центрального канала.
Устанавливаем параметры кодирования в соответствии с параметрами исходника и сохраняем полученную AC3-шную дорожку. Если планируется дальнейшая обработка полученного трека, то я обычно кодирую звук с максимальным битрейтом в 640 килобод.
Полученная таким образом AC3-шная дорожка будет по своему звучанию практически идентичной оригиналу, и в ней будут полностью отсутствовать искажения звуковой картины.
Все это хорошо, но если уже имеется DVD с “убитым” звуком,
над которым уже успели поработать криворукие товарищи? В принципе и в этом случае
можно восстановить звук почти полностью,
Действуем по той же схеме. Только выдираем центральные каналы из русской и английской дорожек. Первым делом синхронизируем русскую дорожку с английской с точностью до семпла. При этом двигать нужно, естественно, русскую дорожку. Обычно она отстает от оригинала миллисекунд на двадцать. Берем какой-либо узкий пик в звуке и ищем соответствие.
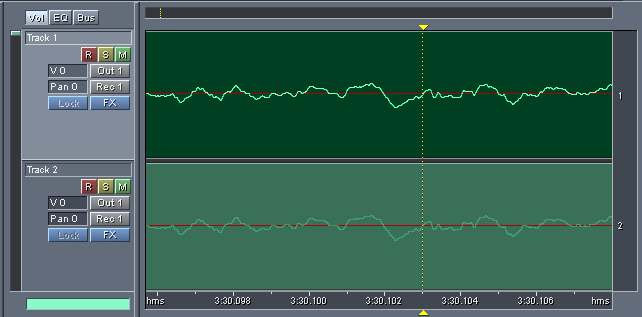
Сильно компрессировать перевод, как это делалось с чистой озвучкой, нельзя. Кривую компрессии нужно подбирать индивидуально. В наиболее общем случае делаем подобную кривую:
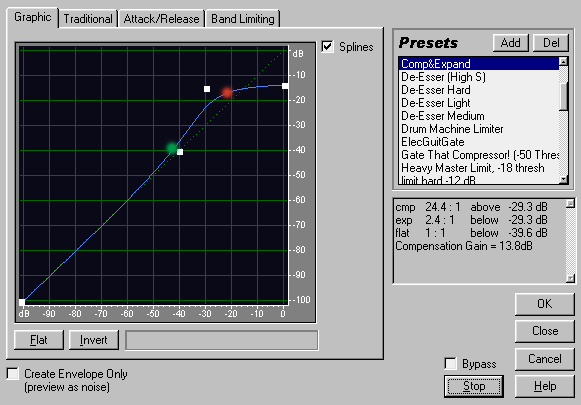
При этом перевод должен располагаться по амплитуде выше красной точки на графике и соответственно подвергаться компрессии, а забитый оригинальный звук преимущественно между красной и зеленой точками, и таким образом подтягиваться в паузах перевода ближе к уровню озвучки. В каждом конкретном случае эти уровни уникальны.
Модулировать уровень английской дорожки имеет смысл, только если оригинал в переводе забит уж очень сильно.
Кривую модуляции компрессированной озвучки нужно делать плавнее, т.к. в сигнале перевода уже присутствует оригинальный звук.
После обработки в модулированную озвучку дополнительно можно подмешать оригинальный центр с уровнем –7, –9 децибел для достижения более качественного звучания.
Надо добиваться всеми возможными способами, чтобы заново смикшированный центральный канал по огибающей амплитуды походил на оригинал.
После создания нового трека озвучки он заново сжимается уже описанным методом.
Таким образом иногда удается вытянуть изначально не плохой, но отвратительно смикшированный перевод. И фильм, от которого с первого взгляда тошнило, вдруг становится вполне возможно смотреть.
Neiromaster. © 2003-03-11
Разрешается свободное распространение и перепечатка данной статьи, при условии сохранения оригинального текста, имени автора и обязательной ссылки на этот сайт.
|